Boggle Roundup: My Fifteen Minutes of Fame
It’s been four months since I announced my big Boggle result. This post will recap what’s happened since then.
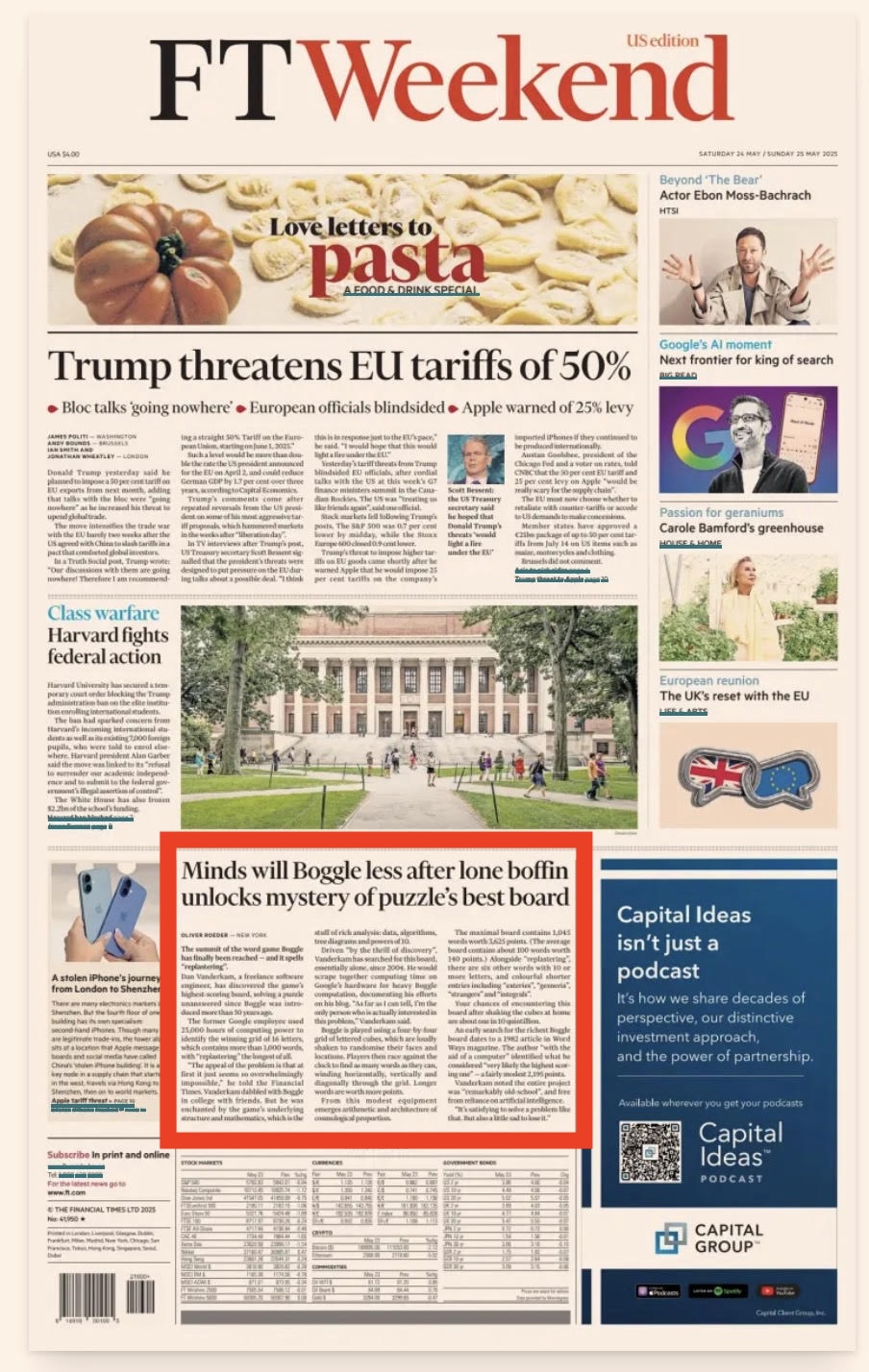
What’s a Boffin?
My announcement post got some play on Hacker News (it made it to the top five) but, if I’m honest, I was a bit disappointed that it didn’t blow up more.
In a bit of a hail mary, I cold emailed Ollie Roeder, who’d written a book (Seven Games) about how computers have changed competitive games like Chess, Checkers, Scrabble and Bridge. Ollie was clearly the right guy to message! Things moved very quickly. He pitched the story to his bosses at the Financial Times and interviewed me the next day. Then they sent out a photographer to shoot me.
The headlines in that weekend’s Financial Times: Pasta, Tariffs, Harvard, and… Dan’s Boggle project! The headline calls me a “lone boffin.” I had to look up what that meant, apparently it’s a Britishism.
Ollie’s article is excellent. I loved all the diagrams they created. People particularly seemed to like my quote that “as far as I can tell, I’m the only person who is actually interested in this problem.” I have to admit, I did say that!
So in the end, I got my 15 minutes of fame. It was great to get recognition, but in particular I appreciated that this coverage validated the work in the eyes of my less technical friends.
- Lone coder cracks 50-year puzzle to find Boggle’s top-scoring board
- I was interviewed for the BBC Global News podcast on May 24, 2025, but it’s no longer online (I have a copy).
Who can vouch for me?
In the announcement post, I said that I intended to write a paper about my result and the methodology. Now I’ve done that. You can find in on arXiv.org:
- 📝 A Computational Proof of the Highest-Scoring Boggle Board (PDF, 14 pages)
A few notes here:
- It had been ~15 years since I last used LaTeX to write a paper. After writing my draft in Markdown, I spent several hours trying to get the LaTeX stack installed on my Mac and rendering something legible. I failed. Instead, I tried Typst and had a great-looking paper in minutes. I really hope that Typst takes over the publishing world and lets us forget about this piece of badly-aging 1980s software.
- To post a paper on arXiv.org, one either needs a .edu email address or someone who can endorse you. This endorser must have posted 3+ papers in the past five years in relevant areas on the site. I spent most of a day trying to find anyone I knew professionally who met this criterion before thinking of Martin Wattenberg, who I worked with at Google. He was “honored” to endorse me. Thanks, Martin!
- In writing the paper, I learned about Evolutionary Strategies and Binary Decision Diagrams. Binary Decision diagrams have been around since the 1980s and are very well-studied, but I’d never run across them before. They are analogous to my insight about making choices in a fixed order. No major insights came from this, but knowing that your data structure has a name is helpful for explaining it.
I’d like to get this published in a peer reviewed journal, but I haven’t made any progress there.
New optimizations and results
There were many loose ends and unexplored ideas when I published my announcement. I’ve continued to tinker on the Boggle project since then, though not with the same level of intensity. I found many incremental improvements that slightly reduced RAM usage, clarified the code or sped things up.
But there was also one big optimization that I found: in one particular situation, I was double-counting words when I didn’t need to. This is the motivating example:
E B E
E F E
You can find “BEEF” four different ways. In a real Boggle game, you only get to score it once. But we’re playing Multiboggle, where we relax this restriction to get a better problem structure. Even here, though, you can remove some of the duplicates. You only need to count the left BEEF and the right BEEF. The two ways of finding each of those use the same letters to form the same word, and they can be de-duped.
Fixing this eventually resulted in something like a 5-10x speedup for the hardest boards and a ~3x speedup overall.
With the new optimization, I asked my friend to run the Boggle solver using the NASPA23 dictionary, which is used in Scrabble competitions. He accidentally ran it on OSPD5 instead. Once we realized that, he kicked off a new job, so we got two new results. As with ENABLE2K, the board you find with hillclimbing is, in fact, the global optimum.
Side quests

The highest-scoring board with a 16-letter word ("charitablenesses")
My main goal was to prove the highest-scoring 4x4 Boggle board. The key result here is that the board you find via hill-climbing is, in fact, the best board.
But I also worked on some tangentially-related side quests that wound up giving unexpected insight into why that’s the case:
- Finding the board with the most words is just a matter of changing the scoring function. Instead of getting more points for longer words, you get one point for each. I’ve proven that hillclimbing finds the most word-dense board for 3x4 Boggle, and I’d be shocked if the same weren’t true for 4x4.
- What’s the highest-scoring board with a 16- or 17-letter word? (A 17-letter word must contain a “Qu.”) This winds up being a very different problem since you can enumerate all Hamiltonian paths through the Boggle board (there are 68,115 paths through a 4x4 board) and score each (path, 16/17-letter word) pair. The highest-scoring board with a 16-letter word is hclbaiaertnssese which contains ”charitablenesses” and the best board with a 17-letter word is qaicdrneetasnnil with ”quadricentennials”. These boards both score considerably fewer points than the overall best board, which contains no words longer than 12 letters. From this exercise, I learned that many wordlists top out at 15 letters, since they’re designed for Scrabble.
- It’s strange that an 8-letter and 12-letter word both score 11 points. What if scoring were exponential? So 3 letters = 1 point, 4=2, 5=4, etc.? This would reward boards with very long words. In this case, hill-climbing does not find the best board. You can run it as long as you like, but enumerating the 16- and 17-letter words finds a better board.
The insight from this last point is that hill-climbing works for high-scoring and word-dense boards because the fitness landscape is quite stable. Small changes to a board do not produce large changes in the score. Whereas if 50% of your score comes from one long word, any small change will ruin that.
Dead ends
It still takes ~10,000 CPU hours to “break” 4x4 Boggle. That’s a lot. If it were 10-20x faster, it would be easier to fill out the grid of best board by dictionary, most word-dense boards, etc.
I’ve had quite a few ideas for further optimization but, except for the double-counting issue, none of them have really panned out:
- The order in which you force cells is important, but the best choice seems very hard to predict in advance for any particular board class. The order I’ve been using (center, edges, corner) is intuitive and pretty good.
- Limited-depth merging. My algorithm does a lot of deep tree-merging. If the nodes way down the tree are never visited later, then maybe a shallow merge would save time. I was optimistic about this, but it turned out to be a total wash.
- Partial-board evaluation. As you force more and more cells to have a specific letter, you start to form a real Boggle board. You can get a better bound on the score by evaluating this as a true Boggle board (no dupes) rather than a Multiboggle board. This was expensive, but helpful for 5x5 Boggle. It’s less helpful for 4x4, but did lead me to the key insight about how I was double-counting words.
- DAG optimization. Inspired by reading about Binary Decision Diagrams, which dedupe subtrees, I revived node de-duping from earlier this year, but in a more clever way. This reduced the memory usage for the initial tree by something like 5x at some CPU cost, but remarkably this reduced memory footprint had no impact on subsequent runtime. This was a disappointment.
I also poked around at 5x5 Boggle, but I think it’s basically hopeless with the current approach. Whereas solving 4x4 Boggle takes ~10,000 CPU hours, 5x5 would take something like a million years. I’ve never played 5x5 Boggle. My main interest here would be in proving or disproving JohnPaul Adamovsky’s claims.
Many people have suggested using SMT/ILP tools like Gurobi or Z3 to solve this problem. They often express confidence that this will work, but I’ve yet to see any evidence that this is the case and I’ve seen some evidence that it isn’t. I hope I’m wrong here! If you’re an expert with these tools and interested in this problem, please take a crack at it. I’d be happy to help.
What’s next?
I’m pretty rapidly running out of ideas. Most likely I’d try to visualize the trees and get new insights and ideas there. It might also be the case that some of the “Dead Ends” are actually good ideas and I’ve just missed something, like with my sad TODO from 2009.
But realistically, I think I’m ready to wrap up this project. I’ve been saying that since February, but now I think I really mean it 🙂. Time to move on. I do plan to publish one more blog post as a sort of retro on the project and what it’s like to work on a hard problem like this.
Please leave comments! It's what makes writing worthwhile.
comments powered by Disqus