02.23.13
Posted in Uncategorized at 1:34 pm by danvk
According to Wikipedia, there are twelve living people born in the 1800s:
| # |
Name |
Sex |
Birth date |
Age |
Residence |
| 1 |
Jiroemon Kimura |
M |
1897 April 19 |
115y 310d |
Japan |
| 2 |
Misao Okawa |
F |
1898 March 5 |
114y 355d |
Japan |
| 3 |
Maria Redaelli-Granoli |
F |
1899 April 3 |
113y 326d |
Italy |
| 4 |
Elsie Thompson |
F |
1899 April 5 |
113y 324d |
United States |
| 5 |
Jeralean Talley |
F |
1899 May 23 |
113y 276d |
United States |
| 6 |
Susannah Jones |
F |
1899 July 6 |
113y 232d |
United States |
| 7 |
Bernice Madigan |
F |
1899 July 24 |
113y 214d |
United States |
| 8 |
Soledad Mexia |
F |
1899 August 13 |
113y 194d |
United States |
| 9 |
Evelyn Kozak |
F |
1899 August 14 |
113y 193d |
United States |
| 10 |
Mitsue Nagasaki |
F |
1899 Sept. 18 |
113y 158d |
Japan |
| 11 |
Emma Morano-Martinuzzi |
F |
1899 Nov. 29 |
113y 86d |
Italy |
| 12 |
Grace Jones |
F |
1899 Dec. 7 |
113y 78d |
United Kingdom |
These are the verified people, which means that the Gerontology Research Group has validated at least three documents mentioning their date of birth. Wikipedia lists at least 50 others whose claims do not meet this stringent standard.
So how long will it be until we can completely close the door on the 19th century? Wikipedia gives the odds of surviving your 114th and 115th years as about 30%, in which case we’d expect the last survivor to die in the next three years. On the other hand, if Grace Jones turns out to be another Jeanne Calment, then we may have to wait another ten!
Update (August 2013): this list is down to eight.
Permalink
02.22.13
Posted in Uncategorized at 7:45 am by danvk
I recently saw this map on the delightful “MapPorn” subreddit:
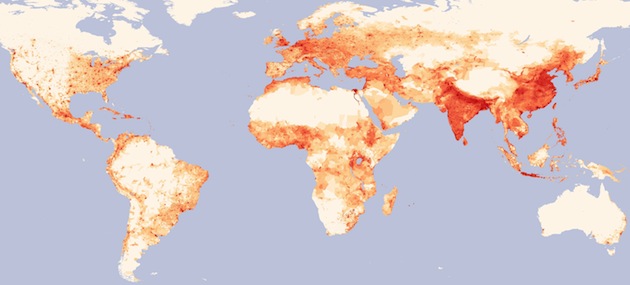
Please click through to the full image, it’s huge!
What I love about this map is that insights spring right out of it. A few that came to my mind:
- The old world (Asia & Europe) is still more heavily populated than the new.
- Population in the new world tends to be more clustered around cities (and roads) than in Europe or Asia.
- Population density in Russia goes much farther east than I’d realized.
- Moscow is much farther east than any other European city.
- All of Egypt’s population lives along the Nile.
- France and Spain are far more centered around their cities than Germany.
- Population density in the United States drops off sharply around the 100th meridian.
- There are no “empty” spots in India or Eastern China.
- Southwest Africa is quite empty.
- Deserts suck. So does tundra.
Do you see anything when you look at the map? The data comes from the Gridded Population of the World project.
Permalink
02.12.13
Posted in Uncategorized at 8:03 pm by danvk
I’ve followed the Global Polio Eradication Initiative for the past few years, ever since I watched The Final Inch, a short documentary which chronicles the effort.
The Initiative recently released a draft of their 2013–2018 Endgame Strategic Plan. The entire report is good reading, but I found this diagram particularly interesting:

Figure 20. GPS tracking of vaccinators, November 2012
Kasurawa A village, Sokoto state [Nigeria]. Each yellow dot represents one track collected every two minutes. Density of dots is converted into an algorithm to approximate the percentage of geographic area visited by the team. In this graph, more than 50% of the village was not visited.
In the world of disease eradication the “final inch” between near eradication and complete eradication is the hardest. If even a small area isn’t vaccinated, it can create a pocket from which the disease can spring back into a larger cluster of cases.
Going door-to-door in these villages must be hard, tedious work. I can easily imagine a vaccinator claiming that they covered the whole village when, in fact, they did not. The whole multi-billion dollar Polio eradication effort could hinge on whether villages like Kasurawa A are fully or just partially vaccinated.
The GPS trackers are a clever way of doing quality control. It’s hard to argue against concrete evidence like the picture above. In the context of disease eradication, “technology” usually means new vaccines or an improved cold chain. But IT can play a role, too.
Permalink
02.09.13
Posted in programming, web at 11:11 pm by danvk
Over the past month, I’ve been working with imagery from the NYPL’s Milstein Collection. Astute readers may have some guesses why. The images look something like this one:

There are two photos in this picture! They’re on cards set against a brown background. Other pictures in the Milstein gallery have one or three photos, with or without a white border:



To make something akin to OldSF, I’d need to write a program to find and extract each of the photos embedded in these pictures. It’s incredibly easy for our eyes to pick out the embedded photos, but this is deceptive. We’re really good at this sort of thing! Teaching a computer to do makes you realize how non-trivial the problem is.
I started by converting the images to grayscale and running edge detection:

The white lines indicate places where there was an “edge” in the original image. It’s an impressive effect—almost like you hired someone to sketch the image. The details on the stoops are particularly cool:

The interesting bit for us isn’t the lines inside the photo so much as the white box around it. Running an edge detection algorithm brings it into stark relief. There are a number of image processing algorithms to detect lines, for example the Hough Transform or scipy’s probabilistic_hough. I’ve never been able to get these to work, however, and this ultimately proved to be a dead end.
A simple algorithm often works much better than high-powered computer vision algorithms like edge detection and the Hough Transform. In this case, I realized that there was, in fact, a much simpler way to do things.
The images are always on brown paper. So why not find the brown paper and call everything else the photos? To do this, I found the median color in each image, blurred it and called everything within an RMSE of 20 “brown”. I colored the brown pixels black and the non-brown pixels white. This left me with an image like this:

Now this is progress! The rectangles stand out clearly. Now it’s a matter of teaching the computer to find them.
To do this, I used the following algorithm:
- Pick a random white pixel, (x, y) (statistically, this is likely to be in a photo)
- Call this a 1×1 rectangle.
- Extend the rectangle out in all directions, so long as you keep adding new white pixels.
- If this rectangle is larger than 100×100, record it as a photo.
- Color the rectangle black.
- If <90% of the image is black, go back to step 1.
Eventually this should find all the photos. Here are the results on the original photo from the top of the post:

The red rectangles are those found by the algorithm. This has a few nice properties:
- It naturally generalizes to images with 1, 2, 3, 4, etc. photos.
- It still works well when the photos are slightly rotated.
- It works for any background color (lighting conditions vary for each image).
There’s still some tweaking to do, but I’m really happy with how this algorithm has performed! You can find the source code here.
Permalink
