01.14.12
Posted in science at 4:57 pm by danvk
I recently built a version of the CDC’s Vital Statistics database for Google’s BigQuery service. You can read more in my post on the Google Research Blog.
The Natality data set is one of the most fascinating I’ve ever worked with. It is an electronic record which goes back to 1969. Every single one of the 68 million rows in it represents a live human birth. I can’t imagine any other data set which was more… laborious… to create. :)
But beyond the data itself, the processes surrounding it also tell a fascinating story. The yearly user guides are a tour-de-force in how publishing has changed in the last forty years. The early manuals were clearly written on typewriters. To make a table, you spaced things out right, then used a ruler and a pen to draw in the lines. Desktop publishing is so easy now that it’s easy to forget how much standards have improved in the last few decades.
They’ve had to balance the statistical benefits of gathering a uniform data set year after year with a need to track a society which has evolved considerably. In 1969, your race was either “Black”, “White” or “Other”. There was a question about whether the child was “legitimate”. There were no questions about alcohol, smoking or drug use. And there was no attempt to protect privacy — most of these early records contain enough information to uniquely identify individuals (though doing so is a federal crime).
I included four example analyses on the BigQuery site. I’ll include one more here: it’s a chart of the twin rate over thirty years as a function of age.
A few takeaways from this chart:
- The twin rate is clearly a function of age.
- It used to be that older women were less likely to have twins.
- Starting around 1994, this pattern reversed itself (likely due to IVF).
- The y-axis is on a log scale, so this effect is truly dramatic.
- There has been an overall increase in the twin rate in the last thirty years.
- This increase spans all ages.
The increase in twin rate is often attributed to IVF, but the last two points indicate that this isn’t the whole story. IVF clearly has a huge effect on the twin rate for older (40+) women, but it can’t explain the increase for younger women. A 21-year old mother was 40% more likely to have twins in 2002 than she was in 1971.
My guess is that this is ultimately because of improved neonatal care. Twins pregnancies are more likely to have complications, and these are less likely to lead to miscarriages than in the past. If this interpretation is correct, then there were just as many 21-year olds pregnant with twins forty years ago. It’s just that this led to fewer births.
Chart credits: dygraphs and jQuery UI Slider.
Permalink
01.15.09
Posted in astronomy, science at 11:18 pm by danvk
 While I was home over Christmas, my mom asked me to throw out some of the magazines that had piled up in my room over the years. One of those was TIME’s February 1996 cover, “Searching for Other Worlds“. Given the imminent launch of NASA’s Kepler Telescope, it was much more timely than the other headline on the cover: “Dole Drops, Clinton Rises“.
While I was home over Christmas, my mom asked me to throw out some of the magazines that had piled up in my room over the years. One of those was TIME’s February 1996 cover, “Searching for Other Worlds“. Given the imminent launch of NASA’s Kepler Telescope, it was much more timely than the other headline on the cover: “Dole Drops, Clinton Rises“.
The article is a fascinating read now, almost 13 years after it was written. It’s easy to make long-term predictions, knowing that you’ll probably never get called on them. But after 13 years, I can call every single one of the bold predictions in this article. None of them have panned out.
Here are the highlights:
Everyone wants to be the next to find a distant world. The scientists are eagerly awaiting the results from the Infrared Space Observatory (ISO), a newly orbiting European satellite that can detect the faint heat from distant planets. They’re looking forward to the 1997 installation of a new infrared camera on the Hubble Space Telescope, which could take a picture of at least one of the newly discovered worlds.
The ISO was launched successfully, but it certainly did not detect planets. In fact, it’s not even clear to me that this was ever an explicit goal. It did detect dust rings around stars, and was decommissioned on schedule after just over two years of service.
The infrared camera on the Hubble is referring to NICMOS, the “Near Infrared Camera and Multi-Object Spectrometer”. It’s hard to find much information about this on the web. Here are a few images from NICMOS. They’re pretty, but planets they ain’t.
It’s not clear to me that planet-detection was a goal of NICMOS either. The TIME writer may have been prone to exaggeration.
Most promising of all, they’re buoyed by a newly unveiled NASA initiative, known as the Origins project, that will build a generation of space telescopes to search for new worlds. Says NASA administrator Daniel Goldin: “We are restructuring the agency to focus on our customer, the American people.” And the public excitement about this field, he says, “is beyond belief.
Ah, the Origins project. It’s still on-going, and is going to have its first major launch with Kepler in March. Goldin became the longest-ever serving NASA administrator before leaving in 2001.
More than one astronomical discovery has disappeared on a closer look, though, so Marcy and Butler headed for the telescope, determined either to debunk or verify the Swiss team’s claims. Sure enough, says Marcy, after four nights at Lick and many hours of computer time, “everything they’d said about the planet was confirmed.” (Butler and Marcy did, however, show that hints the Swiss team had found a second planet around the same star [51 Pegasi] were mistaken.)
After two months, they had analyzed 60 of the 120 stars in their survey. On the morning of Dec. 30, Butler went to the office to check on the computer’s progress. “When I saw the data come up, I was completely blown away,” he says. It was the telltale signature of the object orbiting around 70 Virginis. Recalls Butler: “It knocked me off the chair.”
Geoffrey Marcy went on to discover 70 of the first 100 extrasolar planets and the first transiting exoplanet. Paul Butler is a co-discoverer of approximately 2/3 of the known exoplanets.
… Such a gigantic scope is utterly beyond current technology, and beyond anything engineers can imagine for the next century as well. But astronomers know they can simulate a huge telescope by orbiting several smaller ones, widely separated, and combining their light electronically. This multimirror device is known as an interferometer, because rather than gathering light directly, it measures interference patterns created when light waves from several mirrors overlap each other.
Unlike traditional NASA projects, which tend to be expensive and complex, this one is relatively modest. “We really don’t want to start out building the Battlestar Galactica,” says Weiler. Instead he will start with a demonstration model by the turn of the century, a device consisting of four to six mirrors a foot or two across. Even at that size, the interim interferometer should be able to spot objects the size of Neptune around nearby stars.
That must be referring to the Space Interferometry Mission (SIM). Its launch date has been pushed back five times thus far and has had its budget almost entirely slashed. Wikipedia says it will be launched “no sooner than 2015″. The scientists involved in the project have regrouped and created SIM lite, which aims to accomplish most of the science goals of the original SIM at reduced cost. Their site is careful not to speculate about any launch dates.
Finally, by about 2010, NASA hopes to launch what it calls the Planet Finder: an interferometer with five 3-ft.-to-6-ft. mirrors spread over 300 ft., orbiting out by Jupiter, where the solar-system dust begins to thin out. The Planet Finder should allow scientists to identify Earthlike planets, which should show up as pale blue dots in images beamed back to ground controllers, and analyze their atmosphere for signatures of life like ozone, oxygen or carbon dioxide.
This is referring to the Terrestrial Planet Finder (TPF), which has been abandoned entirely. It’s too bad. The knowledge we’d glean from this is much more interesting than whatever it is we’re learning on the International Space Station.
The astronomers who are looking for planets, meanwhile, are sounding downright cocky. Butler says that he and Marcy are “close, real close” to finishing the analysis of their remaining 60 stars and that they would not be surprised to find two or more additional planets popping out of the data–perhaps in a matter of weeks. The pair will soon be heading for the Keck Telescope in Hawaii, the world’s largest, to continue the search with even more powerful equipment. Mayor and Queloz, meanwhile, are back at their telescope in Europe. At the same time, dozens of other groups, using instruments ranging from the high-flying Hubble to relatively small scopes, are stepping up their activities. Predicts Marcy: “We are going to find, between us and the Swiss, 10 more planets in the next two years.” Concurs Butler: “Very shortly, there could be more planets known outside the solar system than inside.” Whether or not they are right, the human race has already moved closer to answering the most enduring question about its true place in the cosmos.
There were six planets discovered in 1996 and one more in 1997. So they weren’t off by much. The count currently stands at 335.
A few lessons to take from this experience:
- Reporters tend to exaggerate.
- When a government official makes bold predictions about a 10-15 year program, don’t believe him.
- Don’t bet on space-based astronomy. Almost all of those 335 planets were discovered from the ground.
- Interests shift over time. Everyone in this article is interested in pictures of planets. Now we’re more interested in simpler goals, like transits.
Permalink
10.30.07
Posted in astronomy, personal, science, wikipedia at 11:22 pm by danvk
 Ars Technica has the write up of an experiment performed by two University professors. Instead of assigning an ordinary term paper, they had their students create a new Wikipedia article on some topic pertaining to the course. To summarize the summary, it was a rewarding experience for the students but had some issues. In particular, several of the articles were immediately deleted or merged into other articles. The original PowerPoint is worth skimming if you’re interested.
Ars Technica has the write up of an experiment performed by two University professors. Instead of assigning an ordinary term paper, they had their students create a new Wikipedia article on some topic pertaining to the course. To summarize the summary, it was a rewarding experience for the students but had some issues. In particular, several of the articles were immediately deleted or merged into other articles. The original PowerPoint is worth skimming if you’re interested.
My take: this should absolutely be encouraged. How many term papers ever see the light of day after they’re graded? The paper benefits the student, maybe the professor, but rarely anyone else. Can you imagine how many papers college students have written about Rimbaud’s Drunken Boat? Wikipedia needs you!
I’ve thought about the merits of Wikipedia assignments ever since I started editing back in college. The issue of public exposure wasn’t so important. I’ve had that since I was little. It was mostly the idea of not letting all the research I’d done for a course go to waste. I was so enamored with the idea that I gave it a trial run myself. After writing a term paper on two ancient Greek astronomers in the Fall of 2005, I created articles about their works. It was a good but surprisingly time-consuming experience for me. Putting my work on display for all the world to see forced me to double-check everything I’d written, clarify my reasoning, and introduce explanatory figures and tables. But the finished product was great. Those two articles I wrote are undoubtedly the best online source for their two topics. And they’re unexpectedly deep content for Wikipedia, which is not necessarily known for its coverage of original materials or ancient history.
The main problem with this approach is that Wikipedia may not accept these changes with open arms. The professors made some good points about this in their slides. The Wikipedia way is to start small and rough, and edit your way to a finished product. I did this for my two articles. This is the way papers are written as well, it’s just that the process is less visible. What’s more, it helps to be familiar with Wikipedia culture before making major edits. For the students whose articles were deleted or merged, I’m sure they could have asked whether there articles were appropriate on some talk page or another. For contributors not familiar with Wikipedia’s style, their contributions will be a heaping mass of words in need of copyediting. This would be even more important if the students had been assigned to edit an article, rather than write one from scratch.
All in all, if done well, this use of Wikipedia can be great for both the students and the community. Here’s the money quote from one of the students:
This assignment felt so Real! I had not thought that anything I wrote was worth others reading before, but now I think what I contributed was useful, and I’m glad other people can gain from my research.
Permalink
08.28.07
Posted in astronomy, news, personal, science at 3:05 am by danvk
It’s just entered totality, check it out if you’re awake. It’s shocking how many lights my apartment complex still has on at 3 AM. Although this is an unusually long eclipse, it’s going to be a brief one for me. Lunar eclipses are way cooler when they happen at a more reasonable time.
Permalink
04.06.07
Posted in programming, science, wikipedia at 11:50 pm by danvk
While reading Wikipedia’s Mandelbrot set article, I stumbled upon the exceedingly cool Buddhabrot, and the even cooler Nebulabrot:
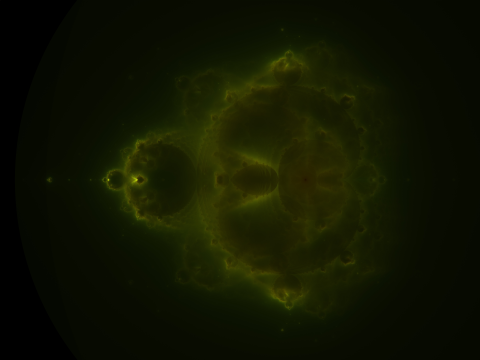
I’ll write more about the math later, but what I find most interesting about it is how it naturally fills in the “boring space” inside the Mandelbrot set:

The interior of the Nebulabrot is also a fractal, as a zoom shows:

Those little buds are all Mandelbrots.
Being a CS-type, once I saw the definition, I immediately set out to render the most detailed Nebulabrot ever seen. It’s 10240×7680 and gorgeous. Here are some zooms (click for full-res versions):

The most “nebular” part
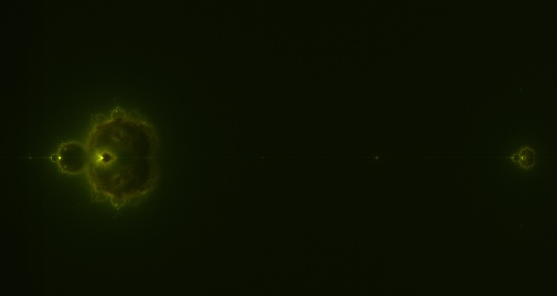
“Island universes” along the negative x-axis
Here’s a link to the full JPEG (4.3MB) and the full PNG (44 MB).
If you zoom all the way in, you’ll see some graininess, even in the PNG. This isn’t a compression artifact. It’s a hint of further structure. If I’d cranked up the dwell limit in my rendering, the noise would have been even more miniature Mandelbrot sets!
Update: MarkCC over at Good Math, Bad Math has a post about MapReduce that discusses the way I generated this at length.
Permalink
{kind=link}
{kind=link}