02.16.07
Posted in boggle, programming at 12:07 am by danvk
I got curious about the programming language D after noticing it outperform C++ in the somewhat-silly Computer Language Shootout and reading Steve Yegge’s thoughts on it. I’ve played around it for the past few days. Here’s some thoughts.
First of all, D is what you might call a “low PageRank language.” If you search for ‘D’, there’s nothing related to the language until result #15. The next result isn’t until #160, and it’s pretty random. Contrast that with C. This makes searching for help on D almost impossible. Try “D slow file I/O” for a taste. This isn’t necessarily Google’s fault, either. There’s just not that many good D resources online yet.
Read the rest of this entry »
Permalink
02.10.07
Posted in boggle, programming at 10:24 pm by danvk
Last time, we used Tries to get a 20x speedup of an already-fast Boggle program. This time, we’ll ferret out the largest remaining bottleneck to produce an even faster Boggler.
What are the main operations that we perform in solving a Boggle board? There’s 1) word lookup, 2) checking if we’ve previously found a word, 3) checking if a letter starts a word and 4) recursion. Here’s how much time they take:
| Operation |
Complexity |
| Word Lookup |
Memory access (Trie::CompletesWord) |
| Previously found? |
Hash lookup/insertion |
| Starts a word? |
Memory access (Trie::StartsWord) |
| Recursion |
Subroutine call |
We’re not going to do better than a memory access or a subroutine call. But who knows how long a hash lookup/insert takes? It’s O(1), but who knows what that constant factor is? It’s certainly more time than a memory access. Let’s see if we can replace that hash lookup/insert with another memory access. We’ll go through a couple of ideas.
Trie annotation
The Trie reduces CompletesWord and StartsWord to memory lookups by storing their results in each node (the is_word and children properties). So why not add another boolean property, found, to each Trie node.
This will clearly reduce the check for whether we’ve found a word to a memory access. The problem is that, if we’ve found a word on one board, we haven’t necessarily found it on the next. So when we’re done solving a board, we need to go back and clean up the Trie. That requires another data structure to track which Trie nodes we’ve marked and an extra loop to reset their found property after every board. That’s at least four memory accesses, not just one.
What’s more, this approach destroys the thread safety of the Trie. Since the Boggler can write to the Trie as well as read it, multiple solvers could easily mess each other up.
This approach works fairly well in practice, but it’s more complex than it seems at first.
Bit Vector
This is inspired by the thread safety argument against Trie annotation. Instead of storing the found bit in the Trie, why not store it somewhere else? Each thread will have a store, so thread safety isn’t an issue. This approach isn’t so different than the hash table approach we used last time, except that it uses a bit vector so it’s faster but uses more memory.
This approach has many drawbacks. First of all, how do you map pointer addresses to locations in a bit vector? There’s a lot of places that a pointer can point to, and there needs to be a bit in the bit vector for all of them. In practice, we’d measure the extent of the Trie in memory and adjust for memory alignment and the number of bits in a word. Unfortunately, you still wind up with a bit vector that’s not that much smaller than the Trie itself.
The bit vector has the same clearing problem after the board has been solved. Using bzero to clear the whole vector every time has a dramatic effect on perf, so you wind up using an extra array to track which bits you’ve set, just like the annotation strategy. This is way more complex than the first idea, but it is thread-safe.
Annotation revisited
This approach took me forever to come up with, but I think it’s the best.
Instead of annotating the Trie with a boolean found value, we can annotate it with a full 32-bit integer. The Boggler keeps track of how many boards it’s solved and stores that value in the Trie node of each word it finds. When it finds a word again, it compares the found value in that node against the board number. If they’re the same, that word has been found on this board. Otherwise it hasn’t. The beauty of this approach is that we don’t need to clean up after ourselves. It’s fine to leave a mess in the Trie, because that mess will never equal the next board number.
We’ll have to do a complete sweep of the Trie to clean out the board numbers when we overflow the board counter, but that happens only once every 2^32 = 4 billion boards, so it’s not a serious concern.
This approach is the simplest, since we don’t need any auxiliary data structures. It’s also the fastest, since we don’t have to clean up after ourselves. But it’s not thread-safe, which is its only major drawback.
The code
Here’s the new stuff in trie.h:
inline void Mark(unsigned mark) { mark_ = mark; }
inline unsigned Mark() const { return mark_; }
unsigned mark_;
We need to add a variable to count the number of boards we’ve processed in boggler.h:
unsigned num_boards_;
And here’s the goodies from boggler.cc:
void ClearMarks(Trie* t) { // NEW
t->Mark(0); // NEW
for (int i=0; i<kNumLetters; i++) // NEW
if (t->StartsWord(i)) // NEW
ClearMarks(t->Descend(i)); // NEW
}
// Returns the score from this portion of the search
void Boggler::Solve(int x, int y, int len, Trie* t) {
prev_[x][y] = true;
len += (bd_[x][y]=='q'-'a' ? 2 : 1);
if (t->IsWord()) {
if (t->Mark() != num_boards_) { // NEW
score_ += kWordScores[len]; // NEW
t->Mark(num_boards_); // NEW
}
}
for (int dx=-1; dx<=1; ++dx) {
int cx = x + dx;
if (cx<0 || cx>3) continue;
for (int dy=-1; dy<=1; ++dy) {
int cy = y + dy;
if (cy<0 || cy>3) continue;
if (prev_[cx][cy]) continue;
if (t->StartsWord(bd_[cx][cy]))
Solve(cx, cy, len, t->Descend(bd_[cx][cy]));
}
}
prev_[x][y] = false;
}
int Boggler::Score(const char* letters) {
if (!ParseBoard(letters)) return -1;
score_ = 0;
for (int i=0; i<16; ++i)
Solve(i/4, i%4, 0, dict_->Descend(bd_[i/4][i%4]));
num_boards_++; // NEW
if (!num_boards_) { // NEW
ClearMarks(dict_); // NEW
num_boards_ = 1; // NEW
}
return score_;
}
That’s about a 15 line change total. What does it buy us?
$ ./perf
Loaded 172203 words.
Testing perf on 50000 boards...
50000 boards in 4.82284 secs => 10367.35 bds/sec
Average board score: 141.1734 pts/bd
That’s another 65% speedup from last time. It’s certainly not 20x, but impressive nonetheless.
Now that we’ve got a lightning-fast Boggle solver we can solving interesting problems with it. Until next time, here’s the source.
To recap, here’s how far we’ve come:
| Program |
Speed |
Change |
Improvement |
| Original |
.004 b/s |
- |
Really simple Ruby |
| Stems |
17.5 b/s |
4000x |
Used stems to prune the DFS |
| C++ |
310 b/s |
18x |
Converted Ruby to C++ |
| Tries |
6271 b/s |
20x |
Use Tries instead of hashes |
| Final |
10367 b/s |
65% |
Annotate the Trie with board counter |
That’s a factor of six million improvement since our first try. It’s interesting to note that the final 600x of improvements all came from replacing O(1) operations with other O(1) operations.
Permalink
02.06.07
Posted in boggle, programming at 2:29 am by danvk
This is the sixth installment in an ongoing series about Boggle. See also 1, 2, 3, 4 and 5.
We’ve talked before about why Tries are the perfect data structure for solving Boggle boards. Today we’ll adapt the C++ program from yesterday’s post to use them.
Here’s a picture of part of a Trie:
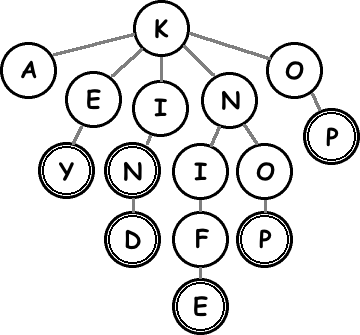
There are three important operations that we can perform quickly on a Trie node:
- Check whether the current node completes a word
- Check whether a particular character leads to more words
- Descend to a child node
So, in addition to some convenience functions, our Trie interface will need to support these operations. Here’s what I came up with:
const int kNumLetters = 26;
class Trie {
public:
Trie();
virtual ~Trie();
// FAST access functions
inline bool IsWord() { return is_word_; }
inline bool StartsWord(int i) { return children_[i]; }
inline Trie* Descend(int i) { return children_[i]; }
// Slower utility functions
void AddWord(const char* wd);
int LoadFile(const char* filename);
bool IsWord(const char* wd) const; // Look up a full word
unsigned int size() const; // Total # of words
private:
Trie* children_[kNumLetters];
bool is_word_;
};
As you can see, the big three operations are all fast inline accessors. There’s one nuance worth talking about here: why do StartsWord and Descend take integers? In pictures of Tries, the edges are usually labeled with strings, or at least characters. This is partially a performance optimization: by mapping ‘a’..’z’ to 0..25, the program can avoid lots of annoying additions and subtractions. It also forces us to treat the ‘qu’ die specially. From now on, we’ll consider the letter ‘q’ to stand in for “qu”. We’ll have to be careful to filter words containing a ‘q’ not followed by a ‘u’ from the dictionary to make this work. We’ll also change our input interface to reflect this. Since each cell can be represented with exactly one character, there’s no reason to separate them with spaces anymore. Where we used to write “a b c d e f g h i j k l m n o p”, we’ll write “abcdefghijklmnop”. This greatly simplifies the board parsing code. I won’t go into any details, but the implementation can be found in trie.cc.
Now for the Boggler class. We’ll try to avoid changing the public interface. The only change will be the format of the boards, from “a b c …” to “abc…” The Boggler will need a Trie to contain its dictionary, but this allows us to remove the words_ and stems_ hashes. Finally, we’ll need some way to remember which words we’ve found. A hash will do fine here, but there’s some trickiness which we’ll get to below:
#include <ext/hash_set>
#include <inttypes.h> // for uintptr_t
using namespace __gnu_cxx; // for hash_set
class Trie;
class Boggler {
public:
Boggler();
int LoadDictionary(const char* filename);
int Score(const char* bd);
private:
bool ParseBoard(const char* lets);
void Solve(int x, int y, int len, Trie* t);
hash_set<uintptr_t> found_;
int bd_[4][4];
bool prev_[4][4];
int score_;
Trie* dict_;
};
So, what the hell is a uintptr_t? We’ll get to that in a sec. What’s more interesting is that the type signature of the recursive Solve method has changed. We no longer know what letters are in the word we’ve found so far, only its length. This is all we need to know for scoring, but it’s a little disconcerting. If we don’t know the characters in the word we’ve found, how can we tell whether we’ve found it before?
The solution is in the Trie. There’s a one-to-one correspondence between nodes in the Trie and words in the dictionary. If we’ve found a word before, then we’ve necessarily been to this Trie node before. So instead of storing the whole word in a hash, we can just store a pointer to the Trie node in its place. This is exactly the kind of dirty hack that I mentioned last time. You can do this in C/C++, but Ruby makes it rather difficult.
That leads us to uintptr_t. The STL won’t just let us put any old pointer into a hash_set. We need to convert it to something that the STL knows how to hash. On a 32-bit system, we could just use an unsigned int or long. But that won’t always work. The uintptr_t data type is an unsigned long that’s guaranteed to have the same number of bits as a pointer. So there we go.
Maybe a picture will clarify things. This shows the Boggle board on the left with all four arguments to the Solve function at each node. On the right is a part of the Trie, annotated with memory addresses. This may have also been an excuse to play with Photoshop..
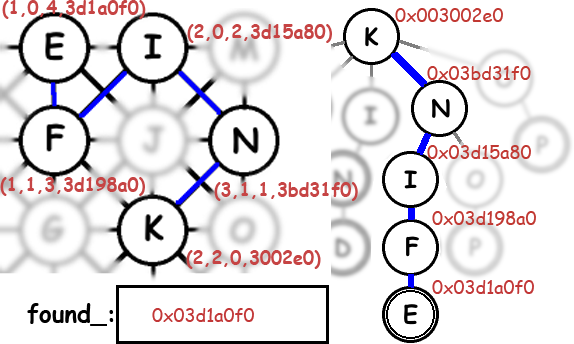
Here’s the juicy bits of the implementation:
// Returns the score from this portion of the search
void Boggler::Solve(int x, int y, int len, Trie* t) {
prev_[x][y] = true;
len += (bd_[x][y]=='q'-'a' ? 2 : 1);
if (t->IsWord()) {
// Convert the Trie node to an int and look it up
uintptr_t hash = reinterpret_cast<uintptr_t>(t);
if (found_.find(hash) == found_.end()) {
score_ += kWordScores[len];
found_.insert(hash);
}
}
// Recur in each possible direction
for (int dx=-1; dx<=1; ++dx) {
int cx = x + dx;
if (cx<0 || cx>3) continue;
for (int dy=-1; dy<=1; ++dy) {
int cy = y + dy;
if (cy<0 || cy>3) continue;
if (prev_[cx][cy]) continue;
if (t->StartsWord(bd_[cx][cy]))
Solve(cx, cy, len, t->Descend(bd_[cx][cy]));
}
}
prev_[x][y] = false;
}
int Boggler::Score(const char* letters) {
if (!ParseBoard(letters)) return -1;
score_ = 0;
for (int i=0; i<16; ++i)
Solve(i/4, i%4, 0, dict_->Descend(bd_[i/4][i%4]));
found_.clear();
return score_;
}
// Board format: "bcdefghijklmnopq"
bool Boggler::ParseBoard(const char* lets) {
for (int i=0; i<16; i++) {
if (!lets[i] || lets[i]<'a' || lets[i]>'z')
return false;
bd_[i/4][i%4] = lets[i] - 'a';
}
return true;
}
Now the moment of truth… what kind of performance do we get out of this? I wrapped a small binary called perf that we’ll be using to measure this from now on. It solves 50,000 pre-defined boards and reports on the time used:
$ ./perf
Loaded 172203 words.
Testing perf on 50000 boards...
50000 boards in 7.97206 secs => 6271.91 bds/sec
Average board score: 141.1734 pts/bd
That’s another 20x improvement over the previous post’s Boggler class!
Fast as this board is, there’s still one major, unnecessary bottleneck left in it. Any guesses? We’ll fix it tomorrow, at which point we’ll have a Boggler that’s about as fast as I know how to make it. Then we can start doing the fun stuff with it.
Complete source code for today’s Boggler can be found here.
Permalink
02.04.07
Posted in boggle, programming at 11:55 pm by danvk
Last time, we talked about Tries, the perfect data structure for Boggle. To take full advantage of Tries, we need to move to a lower-level language than Ruby, which leads to today’s task: convert our Ruby code to C++.
Premature optimization is the root of all evil, so our main goal here is to get a working C++ Boggle solver. We’ll use STL strings and hash tables to produce code that’s as close to the last Ruby program as possible. That being said, I’m going to take this opportunity to extract the Boggle-solving code into its own class. Here’s the interface I came up with:
#include <ext/hash_set>
#include <string>
using namespace __gnu_cxx; // for hash_set
using namespace std; // for string
class Boggler {
public:
Boggler();
int LoadDictionary(const char* filename);
int Score(const char* letters);
private:
bool ParseBoard(const char* lets);
void Solve(int x, int y, const string& sofar);
hash_set<string> words_;
hash_set<string> stems_;
hash_set<string> found_;
string bd_[4][4];
bool prev_[4][4];
int score_;
};
The routines mostly do what their names imply. LoadDictionary populates the words_ and stems_ hashes based on a word list. ParseBoard takes input like “a b c d e f g h i j k l m n o p” and populates the bd_ array. Score parses and scores a board, while Solve is its recursive workhorse.
Before getting to the implementation of this interface, let’s look at a few programs that use it. Here’s one that tests some boards with known scores (try the online boggle solver to test them):
#include "boggler.h"
#include <string>
#include <iostream>
using namespace std;
int main(int argc, char** argv) {
Boggler b;
int words = b.LoadDictionary("words");
cout << "Loaded " << words << " words." << endl;
cout << "b.Score(abcd...) => " << b.Score("a b c d e f g h i j k l m n o p") << " == 18?" << endl;
cout << "b.Score(qu...) => " << b.Score("t c e e v w h b t s t u qu a a e") << " == 94?" << endl;
cout << "b.Score(catd...) => " << b.Score("c a t d l i n e m a r o p e t s") << " == 2338?" << endl;
}
This program is just a quick sanity check. If the Boggler correctly scores those three boards, then it’s doing a whole lot right. Here’s another program that reads boards from standard input and scores each of them. We can use it to test correctness and measure performance:
#include <iostream>
using namespace std;
#include "boggler.h"
int main(int argc, char** argv) {
Boggler b;
b.LoadDictionary("words");
char linebuf[256];
while (cin.getline(linebuf, 256)) {
cout << b.Score(linebuf) << endl;
}
}
Now for the implementation, boggle.cc. The interface requires four functions: LoadDictionary, ParseBoard, Score and Solve. The last is the most interesting, and it can be translated directly from Ruby:
def solve(x, y, sofar)
Prev[x][y]=true
wd = sofar + Bd[x][y]
Found[wd]=true if Words[wd]
Dirs.each do |dx,dy|
next unless (0..3)===(x+dx)
next unless (0..3)===(y+dy)
next if Prev[x+dx][y+dy]
solve(x+dx,y+dy,wd) if Stems[wd]
end
Prev[x][y] = false
end
void Boggler::Solve(int x, int y, const string& sofar) {
prev_[x][y] = true;
string wd = sofar + bd_[x][y];
if (words_.find(wd) != words_.end()) {
if (found_.find(wd) == found_.end()) {
found_.insert(wd);
score_ += kWordScores[wd.size()];
}
}
for (int dx=-1; dx<=1; ++dx) {
int cx = x + dx;
if (cx<0 || cx>3) continue;
for (int dy=-1; dy<=1; ++dy) {
int cy = y + dy;
if (cy<0 || cy>3) continue;
if (prev_[cx][cy]) continue;
if (stems_.find(wd) != stems_.end())
Solve(cx, cy, wd);
}
}
prev_[x][y] = false;
}
The STL syntax for looking up an element in a hash_set is hideous: words_.find(wd) != words_.end()? I can’t understand why there’s no equivalent of Ruby’s has_key? function. What else do you do with hashes? Here’s Score:
int Boggler::Score(const char* letters) {
if (!ParseBoard(letters)) return -1;
score_ = 0;
for (int i=0; i<16; ++i)
Solve(i/4, i%4, "");
found_.clear();
return score_;
}
Simple enough. The other two functions require some STL-fu, but aren’t especially interesting. You can check out the complete source and Makefile from here.
First the sanity check:
$ make
g++ -g -Wall -O3 -march=i686 -c -o test.o test.cc
g++ -g -Wall -O3 -march=i686 -c -o boggler.o boggler.cc
g++ test.o boggler.o -o test
g++ -g -Wall -O3 -march=i686 -c -o scorer.o scorer.cc
g++ scorer.o boggler.o -o scorer
$ ./test
Loaded 172233 words.
b.Score(abcd...) => 18 == 18?
b.Score(qu...) => 94 == 94?
b.Score(catd...) => 2338 == 2338?
So we’ve got correctness. Now the big question: how’s the performance? We’ll get a baseline by scoring zero boards with scorer and then feed it 5,000 boards from a list of 50,000 that I created:
$ time echo '' | ./scorer
-1
real 0m1.431s
user 0m1.294s
sys 0m0.052s
$ time head -5000 test-boards | ./scorer > /dev/null
real 0m17.525s
user 0m17.412s
sys 0m0.107s
$ echo "5000/(17.412-1.294)" | bc -q
310.212185134632088
That’s an 18x improvement over last time, exclusively from moving to C++. There is a Ruby penalty, and 18x is a perfectly believable value for it. I suspect that, if Ruby had a VM, (as it will soon and kind of does already) then this factor could be entirely eliminated. What can’t be eliminated is where we’ll go next. There are some times when it really is worth getting your hands dirty hacking around for performance tweaks. C++ makes those hacks possible, whereas Ruby does not. A simple example: rather than doing all the string addition in Boggler::Solve, we could use a pre-allocated character buffer. I could easily see this gaining a 2-3x performance improvement. But you can’t easily break the string abstraction in Ruby.
Next time we’ll add Tries to the C++ program. You can get the full source for today’s Boggle from here.
Permalink
02.01.07
Posted in boggle, programming at 12:49 am by danvk
So far, we’ve been using hash tables to store our word and prefix lists. These are O(1), constant time, so there’s no room for improvement, right? Not quite. That O(1) for hash tables has a fairly large, unpredictable constant. It also assumes that hashing a string is a constant time operation, which can’t possibly be true. Sure enough, Ruby’s string.hash method does a loop over the characters in the string, so it’s really O(m), where m is the length of the string. There is room for improvement after all!
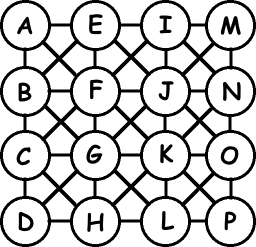
What exactly do we need our data structure to do? When we look at a character on the board, we need to know two things: whether it starts a word (so we’ll need to recur) and whether it completes a word (so we’ll need to score it). As it turns out, Tries are a perfect solution for this problem. Here’s a picture of a small Trie dictionary:
To find the words, read down the lines: K-I-N-D, K-N-I-F-E. Nodes with double circles represent complete words. Suppose the Boggle board looks like this, and we’re looking at the “K”:
We need to know which of the surrounding letters will complete a word. We can read this off the trie immediately: none of them do. We also need to know which letters could result in a word if we kept searching. This is also immediate: “N” and “O” are the only children of “K” in the trie that are next to it on the board. So those are the two avenues we need to explore. Let’s take a look at the “N” path. We go down to the “N” node in the trie and look at its children. None are complete words, but “I” continues a word. And so on until we get to “E”:
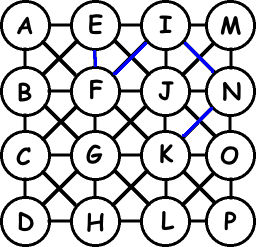
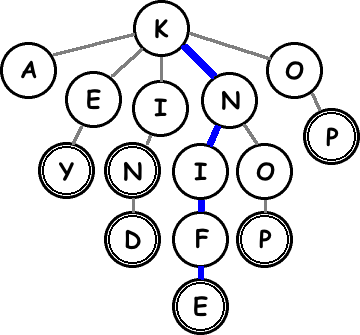
In effect, we’re doing a parallel search through two trees, using each to prune the other. The trie prunes the board search when we get to a sequence of letters that doesn’t start any words. The board search prunes the trie search when we get stuck in a corner or aren’t adjacent to a particular letter.
The real kicker is that tries let us reduce all the operations in our depth-first search to simple memory accesses in the trie. Have we completed a word? The answer’s right where we’re looking in the trie. Does this character start a word? We check if the current trie node has that character as a child. Just a single memory reference. Compared to hash lookups, memory accesses are blazing fast.
Next time we’ll write a simple Trie structure and take it for a spin. Unfortunately, Ruby doesn’t let us take full advantage of the Trie’s Boggle solving powers. I’ve only been able to realize a 2x speed boost from Tries in Ruby. We’ve reached the end of its road. The gains if we go to C++ are far greater, so that’s where we’ll be heading.
Permalink
« Previous Page — « Previous entries
Next entries » — Next Page »