02.06.07
In which we discover that Tries are awesome
This is the sixth installment in an ongoing series about Boggle. See also 1, 2, 3, 4 and 5.
We’ve talked before about why Tries are the perfect data structure for solving Boggle boards. Today we’ll adapt the C++ program from yesterday’s post to use them.
Here’s a picture of part of a Trie:
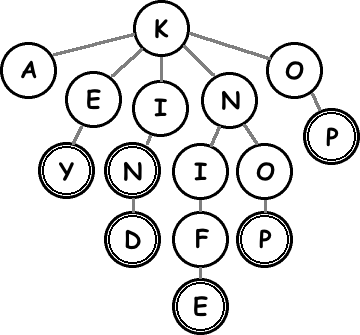
There are three important operations that we can perform quickly on a Trie node:
- Check whether the current node completes a word
- Check whether a particular character leads to more words
- Descend to a child node
So, in addition to some convenience functions, our Trie interface will need to support these operations. Here’s what I came up with:
const int kNumLetters = 26;
class Trie {
public:
Trie();
virtual ~Trie();
// FAST access functions
inline bool IsWord() { return is_word_; }
inline bool StartsWord(int i) { return children_[i]; }
inline Trie* Descend(int i) { return children_[i]; }
// Slower utility functions
void AddWord(const char* wd);
int LoadFile(const char* filename);
bool IsWord(const char* wd) const; // Look up a full word
unsigned int size() const; // Total # of words
private:
Trie* children_[kNumLetters];
bool is_word_;
};
As you can see, the big three operations are all fast inline accessors. There’s one nuance worth talking about here: why do StartsWord and Descend take integers? In pictures of Tries, the edges are usually labeled with strings, or at least characters. This is partially a performance optimization: by mapping ‘a’..’z’ to 0..25, the program can avoid lots of annoying additions and subtractions. It also forces us to treat the ‘qu’ die specially. From now on, we’ll consider the letter ‘q’ to stand in for “qu”. We’ll have to be careful to filter words containing a ‘q’ not followed by a ‘u’ from the dictionary to make this work. We’ll also change our input interface to reflect this. Since each cell can be represented with exactly one character, there’s no reason to separate them with spaces anymore. Where we used to write “a b c d e f g h i j k l m n o p”, we’ll write “abcdefghijklmnop”. This greatly simplifies the board parsing code. I won’t go into any details, but the implementation can be found in trie.cc.
Now for the Boggler class. We’ll try to avoid changing the public interface. The only change will be the format of the boards, from “a b c …” to “abc…” The Boggler will need a Trie to contain its dictionary, but this allows us to remove the words_ and stems_ hashes. Finally, we’ll need some way to remember which words we’ve found. A hash will do fine here, but there’s some trickiness which we’ll get to below:
#include <ext/hash_set>
#include <inttypes.h> // for uintptr_t
using namespace __gnu_cxx; // for hash_set
class Trie;
class Boggler {
public:
Boggler();
int LoadDictionary(const char* filename);
int Score(const char* bd);
private:
bool ParseBoard(const char* lets);
void Solve(int x, int y, int len, Trie* t);
hash_set<uintptr_t> found_;
int bd_[4][4];
bool prev_[4][4];
int score_;
Trie* dict_;
};
So, what the hell is a uintptr_t? We’ll get to that in a sec. What’s more interesting is that the type signature of the recursive Solve method has changed. We no longer know what letters are in the word we’ve found so far, only its length. This is all we need to know for scoring, but it’s a little disconcerting. If we don’t know the characters in the word we’ve found, how can we tell whether we’ve found it before?
The solution is in the Trie. There’s a one-to-one correspondence between nodes in the Trie and words in the dictionary. If we’ve found a word before, then we’ve necessarily been to this Trie node before. So instead of storing the whole word in a hash, we can just store a pointer to the Trie node in its place. This is exactly the kind of dirty hack that I mentioned last time. You can do this in C/C++, but Ruby makes it rather difficult.
That leads us to uintptr_t. The STL won’t just let us put any old pointer into a hash_set. We need to convert it to something that the STL knows how to hash. On a 32-bit system, we could just use an unsigned int or long. But that won’t always work. The uintptr_t data type is an unsigned long that’s guaranteed to have the same number of bits as a pointer. So there we go.
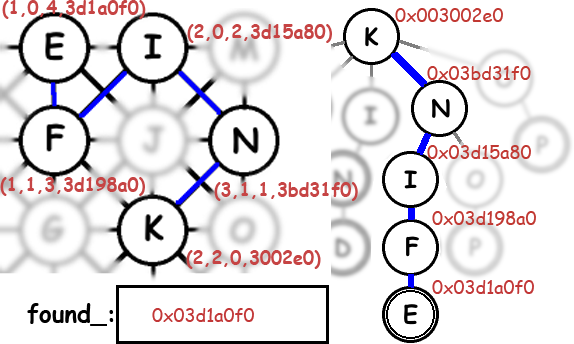
Maybe a picture will clarify things. This shows the Boggle board on the left with all four arguments to the Solve function at each node. On the right is a part of the Trie, annotated with memory addresses. This may have also been an excuse to play with Photoshop..
Here’s the juicy bits of the implementation:
// Returns the score from this portion of the search
void Boggler::Solve(int x, int y, int len, Trie* t) {
prev_[x][y] = true;
len += (bd_[x][y]=='q'-'a' ? 2 : 1);
if (t->IsWord()) {
// Convert the Trie node to an int and look it up
uintptr_t hash = reinterpret_cast<uintptr_t>(t);
if (found_.find(hash) == found_.end()) {
score_ += kWordScores[len];
found_.insert(hash);
}
}
// Recur in each possible direction
for (int dx=-1; dx<=1; ++dx) {
int cx = x + dx;
if (cx<0 || cx>3) continue;
for (int dy=-1; dy<=1; ++dy) {
int cy = y + dy;
if (cy<0 || cy>3) continue;
if (prev_[cx][cy]) continue;
if (t->StartsWord(bd_[cx][cy]))
Solve(cx, cy, len, t->Descend(bd_[cx][cy]));
}
}
prev_[x][y] = false;
}
int Boggler::Score(const char* letters) {
if (!ParseBoard(letters)) return -1;
score_ = 0;
for (int i=0; i<16; ++i)
Solve(i/4, i%4, 0, dict_->Descend(bd_[i/4][i%4]));
found_.clear();
return score_;
}
// Board format: "bcdefghijklmnopq"
bool Boggler::ParseBoard(const char* lets) {
for (int i=0; i<16; i++) {
if (!lets[i] || lets[i]<'a' || lets[i]>'z')
return false;
bd_[i/4][i%4] = lets[i] - 'a';
}
return true;
}
Now the moment of truth… what kind of performance do we get out of this? I wrapped a small binary called perf that we’ll be using to measure this from now on. It solves 50,000 pre-defined boards and reports on the time used:
$ ./perf Loaded 172203 words. Testing perf on 50000 boards... 50000 boards in 7.97206 secs => 6271.91 bds/sec Average board score: 141.1734 pts/bd
That’s another 20x improvement over the previous post’s Boggler class!
Fast as this board is, there’s still one major, unnecessary bottleneck left in it. Any guesses? We’ll fix it tomorrow, at which point we’ll have a Boggler that’s about as fast as I know how to make it. Then we can start doing the fun stuff with it.
Complete source code for today’s Boggler can be found here.